
Anti-vaxxers love to demand placebo-controlled trials and insist that nothing else will suffice for demonstrating vaccine safety. This approach to medical research is flawed for a number of reasons. First, as I’ve explained previously, new vaccines are, in fact, tested against placebos. Truly novel vaccines (e.g., COVID vaccines) get tested against an inert, saline placebo (e.g., Polack et al. 2020), while updates to existing vaccines typically get tested against the previous versions of the vaccine, because those versions already have known safety and effectiveness profiles.
There is, however, a more fundamental issue with this insistence on placebo-controlled trials. Namely, they are not actually the best tool for examining vaccine safety, and cohort and case-control trials are often more useful. I’ve talked about this a number of times before (here, here, and here), but in this post, I want to try a more visual approach and actually show some data to illustrate the point.
As a brief thesis statement, correlation doesn’t automatically equal causation, but a lack of correlation does suggest a lack of causation (see note at end). Therefore, you do not need a placebo-controlled trial to make a statement like “vaccines do not cause autism” (within the statistical limits described below), and other study designs like cohort studies and case-control studies are actually better.
Note: we usually use “correlated” for continuous variables that change together (regressions) and “associated” for discrete variables, but for simplicity, I will just use “correlated” throughout.
Types of studies
There are three types of studies that are most relevant to this post (more details are here).
The first is the classic randomized controlled trial (aka RCT). In medical research, these are usually also placebo-controlled. This design takes a group of subjects, randomizes them into a treatment group (i.e., the group that receives a medicine) and a control group that receives a placebo instead of medicine. Some outcome of interest (e.g., a side effect) is then recorded in each group, and the rates of that outcome are compared.
Next, we have cohort studies. These use the same basic design as randomized placebo-controlled studies, but they are not manipulative. So rather than randomizing people into groups, it simply looks at groups who did and did not take a treatment (often via medical records) then compares the rates of the outcome of interest.
Finally, case-control studies work backwards. They identify a group of people with the outcome of interest (the “cases”) then match them with a group of people who are similar demographically but don’t have the outcome of interest (the “controls”). Then, the rates of a potential cause are compared between the groups.
Why randomize?
At the outset, we need to briefly discuss why randomized controlled trials (which, in medicine, are typically placebo-controlled) are generally so useful, as well as the nature of causation (note that the explanation below is simplified for the sake of brevity).
When we say that two things are correlated, we mean that they change together. So, there is a relationship between the two variables. The problem is that simply being related doesn’t mean that one thing is causing the other. For example, they could both be being caused by a third factor.
To use a famous example, ice cream sales and drowning are positively correlated (they both increase and decrease together). That does not, however, mean that ice cream causes drowning. Rather, a third factor (high temperatures) causes people to buy more ice cream and spend more time swimming (which results in more drowning accidents).
When we are trying to test for causation scientifically, we need to be extremely confident that there is no third factor driving the relationship. This is where randomization comes in. By randomly dividing people into two groups, we spread out all additional factors between the two groups so that no third factor can drive the results. This is the reason why randomized trials can confidently assert causation, while cohort and case-control trials cannot. For those designs, we can do our best to account for confounding factors (third factors) in the models, but it is always possible that we missed something. We just don’t have the confidence that we do with randomization.
So, if you want to say that X causes Y, you need a randomized trial. However, you do not need a randomized trial to say that X does not cause Y.
If you think about this for a second, the reason should be obvious. If X causes Y, then they will inherently, by definition, be correlated. Therefore, if they are not correlated, then X cannot be causing Y. Any time that X causes Y, there will be a correlation. So, no correlation = no causation (see note at end).
This means that a statement like, “vaccines don’t cause autism” does not need randomized, placebo-controlled trials to back it up, and, as we’ll see below, other designs are actually better.
Finally, it is worth mentioning that the purpose of the placebo is to get a good measure of the background experimental error rates (e.g., regression to the mean). This is really important for something like measuring whether a drug improves symptoms. It is substantially less important for outcomes like whether or not patients get an emerging infectious disease or rare side effects (more on placebos here).
The power of cohort and case-control trials
The big limitation of placebo-controlled trials (beyond ethical issues) is that they are really expensive and hard to conduct. They are very time consuming, and it is difficult and costly to recruit participants and get them to stick with the program. As a result, controlled trials generally range from a few dozen to a few hundred participants. Sample sizes of a few thousand are rare (though COVID provided a few exceptions).
This is a huge drawback, because sample size is one of the key factors dictating the power of a test. The larger the sample size, the more power you have to detect the thing you’re testing.
Background rates and the strength of the association also affect a test’s power and determine the sample size needed to detect an effect. Let’s say that you are testing a vaccine to see if it causes side effect X. If that side effect is really common, then you can detect it with a small sample size, but if it is really rare, then you are going to need a much larger sample size to detect it. Further, how often X occurs on its own (for reasons other than the vaccine) also influences your power. If it is really common in the general population, then it is going to be hard to detect the signal from vaccines causing it and, once again, you need a very large sample size. In contrast, if it is rare, then you can detect it with a smaller sample size.
This is where cohort and case-control studies come in. Cohort studies follow the same basic power rules as randomized studies, but because they are cheap and easy to conduct, they can be quite large, often including tens of thousands or even hundreds of thousands of individuals.
Case-control studies are even more powerful because they start with the outcome of interest. So even if the outcome is quite rare, you can get records for a lot of people with that outcome. This makes them substantially more powerful for studying potential causes of rare side effects, and these studies often have samples sizes of thousands of participants.
Simulated results
To illustrate this, I ran a simple simulation. In short, for a given sample size, background rate (how often it occurs without the potential cause), and side effect rate (how often the treatment actually causes it), it ran 500 iterations of generating populations of people who did and did not receive the treatment with the background rates and side effect rates applied. It then analyzed the data using the approach of randomized/cohort studies or case-control studies and returned the percent of “studies” (the 500 runs) where a statistically significant result was found (P < 0.05; see more details below).
I realize the resulting graph can be a bit daunting, so let me walk you through it. Going from left to right, the columns have decreasing background rates. So, in the first column, the outcome is very common in the general population (occurs in 1 in 10 individuals without the treatment), and on the far right, it is rare (1 in 10,000). Going down the rows, the side effect rate from the treatment decreases. So, in the first row, the side effect is very common (the treatment causes it in 1 in 10 patients, in addition to the background rate), and by the last row, it is rare, only being caused in 1 in 1,000,000 patients.
Within each panel, we are seeing the percent of tests (out of 500) where we were able to detect a correlation (significant result) on the y-axis. Keeping in mind that there was a causal relationship in each test. So, anything less than 100% indicates a false negative (an under-powered test). On the x-axis, we have increasing sample sizes (on a log10 scale). Blue results are for randomize/cohort trials, and red indicates case-control trials.
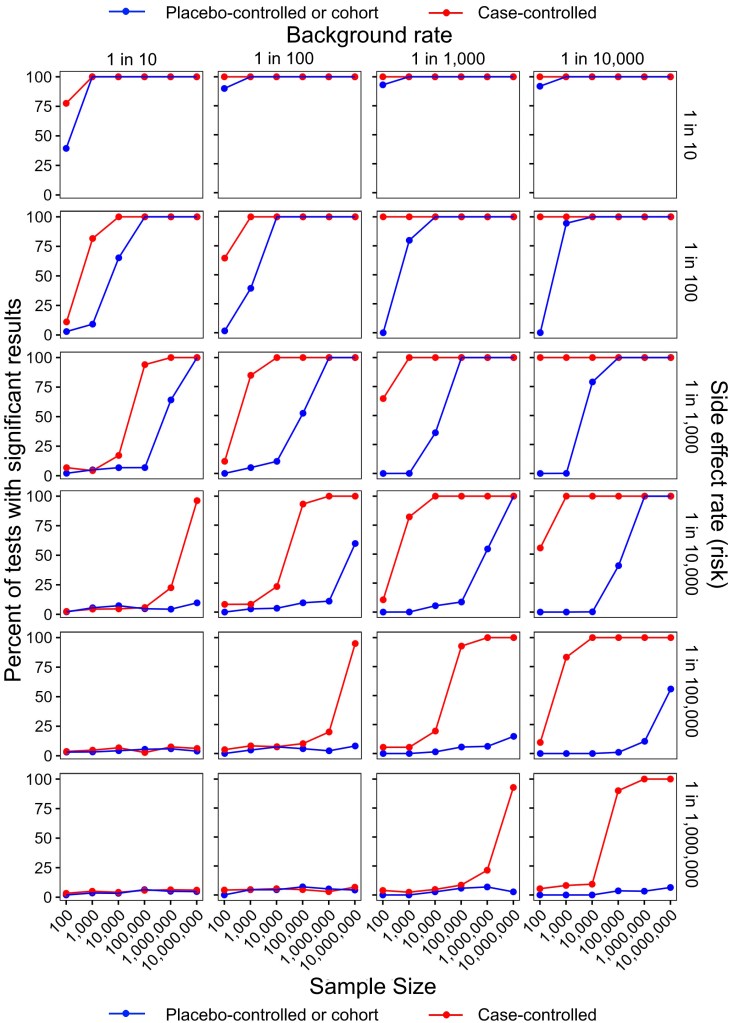
There are several important and clear patterns here:
- Within each row, the rate of positive results increases from left to right (i.e., the lower the background rate, the more powerful the test).
- Within each column, the rate of positive results decreases from top to bottom (i.e., the rarer the side effect, the harder it is to detect).
- Within each panel, the rate of positive results increases from left to right (i.e., the larger the sample size, the more power).
- Case-control studies consistently have more power than randomized/cohort studies, with particularly pronounced differences for rare background and side effect rates.
Before going any further, I want to pause and stress that these are simulated results based on a simplistic scenario. So, the four trends described above apply to the real world, but the exact numbers shown here don’t necessarily apply, and in the real world there would be confounding factors (sex, age, medical history, etc.) that would be built into the models.
Interpreting the negative results
Now we get to a really important caveat about how to interpret negative results (keeping in mind that in my simulation, there was an effect of treatment in each simulation, we just weren’t always able to detect it).
Technically speaking, science never proves anything, and it is particularly problematic to demonstrate a negative. So, when we fail to find a correlation, technically, we have not shown that there is NO effect. Rather we have shown that IF there is an effect, it was too rare to detect with our sample size.
Keep in mind that in real studies, we know both the sample size and the background rate (that’s just the rate in the control group), so the only unknown is the treatment effect (side effect rate, in our example). Therefore, while we cannot conclusively with 100% certainty say that there is no relationship, we can get a sense for how rare it would have to be if it occurred. Thus, we can use the study design, sample size, and background rate to judge how concerned we need to be about the possibility of an undetectable effect. If the study had low power, then it may still be a legitimate concern, but if the study had a high power, then the concern is greatly reduced.
Note that anti-vaccers love to abuse this reality and play word games like demanding to see a study that “proves that vaccines don’t cause autism.” That’s an impossible request. It is never possible to prove that X does not cause Y, but we can show that if X causes Y, it would have to be doing so at such an incredibly low rate that it’s not a big concern (more on that in a sec).
Applying this to vaccines
Finally, let’s bring this all back around to anti-vaccers’ original argument that only placebo-controlled trials are satisfactory for establishing vaccine safety. As you can hopefully now see, that is a really faulty claim, and placebo-controlled trials are actually badly under-powered because of their low sample sizes. If you showed me a randomized, placebo-controlled trial of 1,000 children (a pretty big trial) that failed to find a significant trend for autism, I’d actually agree with you that that study is weak evidence. We know autism is fairly common (it has a high background rate), so that study would only eliminate the possibility of vaccines causing autism at a really high rate. It would still be entirely possible for vaccines to be a substantial cause of autism. That test was just under-powered.
In contrast, there have been several cohort studies of vaccines and autism with sample sizes of several hundred thousand children (Anders et al. 2004; Hviid et al. 2019; Madsen et al. 2002; Jain et al. 2015). Now we are talking about tests with some power; tests that can confidently assert that IF there is a relationship between vaccines and autism, it is a very weak one, and autism is a very rare side effect.
Further, we have case-control studies on vaccines and autism with hundreds or even thousands of children (Destefano et al. 2004; Smeeth et al. 2004; DeStefano et al. 2013; Uno et al. 2015). Again, those are actually very powerful (way more powerful than a randomized trial).
Additionally, there is even a meta-analysis that combined the studies above into one uber study with some truly impressive power (Taylor et al. 2014). Guess what? There was still no correlation. So, we can confidently state that there is no evidence of vaccines causing autism and IF they do, they are doing so at an incredibly low rate.
Stated another way, anti-vaccers are technically correct that we cannot “prove” that vaccines don’t cause autism, BUT we can and have demonstrated that even IF vaccines cause autism, the rate is very, very low. Thus, the notion of vaccines causing an “autism epidemic” is completely falsified. You almost certainly don’t know anyone who has autism because of vaccines because even if that side effect ever occurs, it is very rare.
Conclusion
I have been using autism as an example here, but all of this applies generally to all vaccines and all medical research using these study designs. When we are talking about safety and making claims about side effect rates, randomized placebo-controlled studies are often under-powered and frequently aren’t the best tool. They are great during initial testing, because they will detect common side effects and allow us to assign causation, but once we are talking about side effects that only occur once in a few thousand people, randomized trials are grossly under-powered, and cohort and case-control trials are much better tools for detecting correlation/associations. Randomization is important for assigning causation, but it is not needed to detect correlation, and while correlation does not indicate causation, two things that are causally related will, by definition, be correlated (though the correlation may be hard to detect). As such, anti-vaccers are completely and totally wrong to insist that we don’t know vaccines are safe without placebo-controlled trials. A lack of correlation/association in large cohort and case-controlled studies are great evidence that even if there was a side effect, it would be extremely rare. Thus, anti-vaccers are fundamentally misunderstanding how study designs and statistical power work.
NOTE ON LACK OF CORRELATION: When I say that a lack of correlation indicates a lack of causation, this is true in the strictest sense that if two things are causally related, there will inherently be a relationship between them. However, that does not mean that failing to detect a correlation proves a lack of causation. As seen in the post, tests may simply have been under-powered. Further, there may be time-lag effects or third causes that are also important. So, sample size and study design are important considerations (i.e., did they correctly control for confounding factors?). Nevertheless, my fundamental point remains that a lack of correlation/association in large cohort/case-control studies is good evidence that if there is a causal relationship, it is a weak one with a small effect size.
MODEL DETAILS: This was a stochastic simulation, meaning that there was chance variation in the results, which accounts for some of the “waviness” in the figure. For example, if the background rate was 1 in 10, then each individual in the control population, had a 1 in 10 chance of developing the outcome, but this was determined stochastically. So, for runs with 100 individuals, on average, 10 would have the outcome, but sometimes it would be 9, sometimes it would be 11, etc. Also note that the side effect rate was additive to the background rate, so if background = 1 in 10, and side effect rate = 1 in 10, people who received the treatment had a 2 in 10 chance of developing the side effect. Also note that sample size is per group. So, n = 100 means 100 people in the control group and 100 people in the treatment/case group. For modeling simplicity for the case-control trials, it assumed that half of the total population received the treatment.
Related posts
- How well do you understand placebo effects?
- Masks and COVID vaccines were huge successes; ivermectin and hydroxychloroquine were not
- The hierarchy of evidence: Is the study’s design robust?
- Understanding the reported risks of medicines, foods, toxic chemicals, etc.
- Vaccines and autism: A thorough review of the evidence (2019 update)
- Vaccines are tested against placebos
- When can correlation equal causation?
Litterateur cited
- Anders et al. 2004. Thimerosal exposure in infants and developmental disorders: a retrospective cohort study in the United Kingdom does not support a causal association. Pediatrics 114:584–591
- DeStefano et al. 2004. Age at first measles-mumps-rubella vaccination in children with autism and school-matched control subjects: a population-based study in metropolitan Atlanta. Pediatrics 113:259–266
- DeStefano et al. 2013. Increasing exposure to antibody-stimulating proteins and polysaccharides in vaccines is not associated with risk of autism. J Ped 163:561–567
- Hviid et al. 2019. Measles, mumps, rubella vaccination and autism: A nationwide cohort study. Annals of Internal Medicine.
- Jain et al. 2015. Autism occurrence by MMR vaccine status among US children with older siblings with and without autism. JAMA 313:1534–1540
- Madsen et al. 2002. A population-based study of measles, mumps, and rubella vaccination and autism. New England Journal of Medicine 347:1477–1482
- Polack et al. 2020. Safety and efficacy of the BNT162b2 mRNA Covid-19 vaccine. New England Journal of Medicine 383:2603-2615.
- Smeeth et al. 2004. MMR vaccination and pervasive developmental disorders: a case-control study. Lancet 364:963–969
- Taylor et al. 2014. Vaccines are not associated with autism: and evidence-based meta-analysis of case-control and cohort studies. Elsevier 32:3623-3629
- Uno et al. 2015. Early exposure to the combined measles-mumps-rubella vaccine and thimerosal-containing vaccines and risk of autism spectrum disorder. Vaccine 33:2511–2516

 Science-deniers have a long history of blindly assuming that any research they don’t like must have been corrupted by “big whatever,” and I constantly see people
Science-deniers have a long history of blindly assuming that any research they don’t like must have been corrupted by “big whatever,” and I constantly see people  The “backfire effect” is a psychological phenomenon in which correcting misinformation actually reinforces the false view rather than causing someone to reject it (
The “backfire effect” is a psychological phenomenon in which correcting misinformation actually reinforces the false view rather than causing someone to reject it (