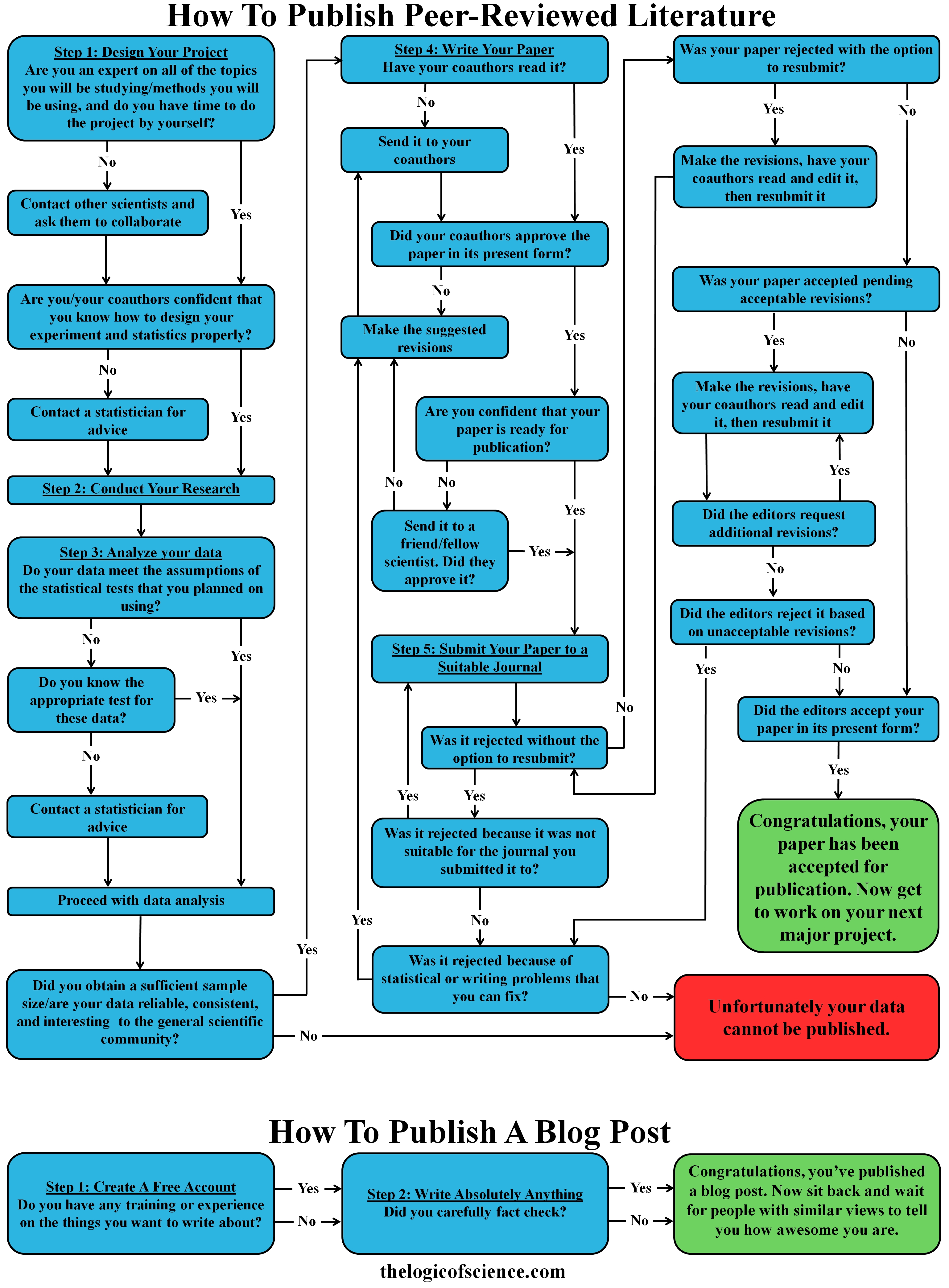
People are extraordinarily prone to confirmation biases. We have a strong tendency to latch onto anything that supports our position and blindly ignore anything that doesn’t. This is especially true when it comes to scientific topics. People love to think that science is on their side, and they often use scientific papers to bolster their position. Citing scientific literature can, of course, be a very good thing. In fact, I frequently insist that we have to rely on the peer-reviewed literature for scientific matters. The problem is that not all scientific papers are of a high quality. Shoddy research does sometimes get published, and we’ve reached a point in history where there is so much research being published that if you look hard enough, you can find at least one paper in support of almost any position that you can imagine. Therefore, we must always be cautious about eagerly accepting papers that agree with our preconceptions, and we should always carefully examine publications. I have previously dealt with this topic by describing both good and bad criteria for rejecting a paper; however, both of those posts were concerned primarily with telling whether or not the study itself was done correctly, and the situation is substantially more complicated than that. You see, there are many different types of scientific studies and some designs are more robust and powerful than others. Thus, you can have two studies that were both done correctly, but both reached very different conclusions. Therefore, when examining a paper, it is critical that you take a look at the type of experimental design that was used and consider whether or not it is robust. To aid you in that endeavor, I am going to provide you with a brief description of some of the more common designs, starting with the least powerful and moving to the most authoritative.
People are extraordinarily prone to confirmation biases. We have a strong tendency to latch onto anything that supports our position and blindly ignore anything that doesn’t. This is especially true when it comes to scientific topics. People love to think that science is on their side, and they often use scientific papers to bolster their position. Citing scientific literature can, of course, be a very good thing. In fact, I frequently insist that we have to rely on the peer-reviewed literature for scientific matters. The problem is that not all scientific papers are of a high quality. Shoddy research does sometimes get published, and we’ve reached a point in history where there is so much research being published that if you look hard enough, you can find at least one paper in support of almost any position that you can imagine. Therefore, we must always be cautious about eagerly accepting papers that agree with our preconceptions, and we should always carefully examine publications. I have previously dealt with this topic by describing both good and bad criteria for rejecting a paper; however, both of those posts were concerned primarily with telling whether or not the study itself was done correctly, and the situation is substantially more complicated than that. You see, there are many different types of scientific studies and some designs are more robust and powerful than others. Thus, you can have two studies that were both done correctly, but both reached very different conclusions. Therefore, when examining a paper, it is critical that you take a look at the type of experimental design that was used and consider whether or not it is robust. To aid you in that endeavor, I am going to provide you with a brief description of some of the more common designs, starting with the least powerful and moving to the most authoritative.
Note: Before I begin, I want to make a few clarifications. First, this hierarchy of evidence is a general guideline, not an absolute rule. There certainly are cases where a study that used a relatively weak design can trump a study that used a more robust design (I’ll discuss some of these instances in the post), and there is no one universally agreed upon hierarchy, but it is widely agreed that the order presented here does rank the study designs themselves in order of robustness (many of the different hierarchies include criteria that I am not discussing because I am focusing entirely on the design of the study). Second, the exact order of the designs that I have ranked as “very weak” and “weak” is debatable, but the key point is that they are always considered to be the lowest forms of evidence. Third, for sake of brevity, I am only going to describe the different types of research designs in their most general terms. There are subcategories for most of them which I won’t go into. Fourth, this hierarchy is most germane to issues of human health (i.e., the causes a particular disease, the safety of a pharmaceutical or food item, the effectiveness of a medication, etc.). Many other disciplines do, however, use similar methodologies and much of this post applies to them as well (for example, meta-analysis and systematic reviews are always at the top). Finally, realize that for the sake of this post, I am assuming that all of the studies themselves were done correctly and used the controls, randomization, etc. that are appropriate for that particular type of study. In reality, those are things which you must carefully examine when reading a paper.
Opinions/letters (strength = very weak)
Some journals publish opinion pieces and letters. These are rather unusual for academic publications because they aren’t actually research. Rather, they consist of the author(s) arguing for a particular position, explaining why research needs to start moving in a certain direction, explaining problems with a particular paper, etc. These can be quite good as they are generally written by experts in the relevant fields, but you shouldn’t mistake them for new scientific evidence. They should be based on evidence, but they generally do not contain any new information. Thus, it would be disingenuous to describe one by saying, “a study found that…” Rather, you can say, “this scientist made the following argument, and it is compelling…” but you cannot conflate an argument to the status of evidence. To be clear, arguments can be very informative and they often drive future research, but you can’t make a claim like, “vaccines cause autism because this scientist said so in this opinion piece.” Opinions should always guide research rather than being treated as research.
Case reports (strength = very weak)
These are essentially glorified anecdotes. They are typically reports of some single event. In medicine, these are typically centered on a single patient and can include things like a novel reaction to a treatment, a strange physiological malformation, the success of a novel treatment, the progression of a rare disease, etc. Other fields often have similar publications. For example, in zoology, we have “natural history notes” which are observations of some novel attribute or behavior (e.g., the first report of albinism in a species, a new diet record, etc.).
Case reports can be very useful as the starting point for further investigation, but they are generally a single data point, so you should not place much weight on them. For example, let’s suppose that a novel vaccine is made, and during its first year of use, a doctor has a patient who starts having seizures shortly after receiving the vaccine. Therefore, he writes a case report about it. That report should (and likely would) be taken seriously by the scientific/medical community who would then set up a study to test whether or not the vaccine actually causes seizures, but you couldn’t use that case report as strong evidence that the vaccine is dangerous. You would have to wait for a large study before reaching a conclusion. Never forget that the fact that event A happened before event B does not mean that event A caused event B (that’s actually a logical fallacy known as post hoc ergo propter hoc). It is entirely possible that the seizure was caused by something totally unrelated to the vaccine, and it just happened to occur shortly after the vaccine was administered.
Animal studies (strength = weak)
Animal studies simply use animals to test pharmaceuticals, GMOs, etc. to get an idea of whether or not they are safe/effective before moving on to human trials. Exactly where animal trials fall on the hierarchy of evidence is debatable, but they are always placed near the bottom. The reason for this is really quite simple: human physiology is different from the physiology of other animals, so a drug may act differently in humans than it does in mice, pigs, etc. Also, the strength of an animal study will be dependent on how closely the physiology of the test animal matches human physiology (e.g., in most cases a trial with chimpanzees will be more convincing than a trial with mice).
Because animal studies are inherently limited, they are generally used simply as the starting point for future research. For example, when a new drug is developed, it will generally be tried on animals before being tried on humans. If it shows promise during animal trials, then human trials will be approved. Once the human trials have been conducted, however, the results of the animal trials become fairly irrelevant. So you should be very cautious about basing your position/argument on animal trials.
It should be noted, however, that there are certain lines of investigation that necessarily end with animals. For example, when we are studying acute toxicity and attempting to determine the lethal dose of a chemical, it would obviously be extremely unethical to use human subjects. Therefore, we rely on animal studies, rather than actually using humans to determine the dose at which a chemical becomes lethal.
Finally, I want to stress that the problem with animal studies is not a statistical one, rather it is a problem of applicability. You can (and should) do animal studies by using a randomized controlled design. This will give you extraordinary statistical power, but, the result that you get may not actually be applicable to humans. In other words, you may have very convincingly demonstrated how X behaves in mice, but that doesn’t necessarily mean that it will behave the same way in humans.
In vitro studies (strength = weak)
In vitro is Latin for “in glass,” and it is used to refer to “test tube studies.” In other words, these are laboratory trials that use isolated cells, biological molecules, etc. rather than complex multi-cellular organisms. For example, if we want to know whether or not pharmaceutical X treats cancer, we might start with an in vitro study where we take a plate of isolated cancer cells and expose it to X to see what happens.
The problem is that in a controlled, limited environment like a test tube, chemicals often behave very differently than they do in an exceedingly complex environment like the human body. Every second, there are thousands of chemical reactions going on inside of the human body, and these may interact with the drug that is being tested and prevent it from functioning as desired. For something like a chemical that kills cancer cells to work, it has to be transported through the body to the cancer cells, ignore the healthy cells, not interact with all of the thousands of other chemicals that are present (or at least not interact in a way that is harmful or prevents it from functioning), and it has to actually kill the cancer cells. So, showing that a drug kills cancer cells in a petri dish only solves one very small part of a very large and very complex puzzle. Therefore, in vitro studies should be the start of an area of research, rather than its conclusion. People often don’t seem to realize this, however, and I frequently see in vitro studies being hailed as proof of some new miracle cure, proof that GMOs are dangerous, proof that vaccines cause autism, etc. In reality, you have to wait for studies with a substantially more robust design before drawing a conclusion. To be clear, as with animal studies, this is an application problem, not a statistical problem.
Cross sectional study (strength = weak-moderate)
Cross sectional studies (also called transversal studies and prevalence studies) determine the prevalence of a particular trait in a particular population at a particular time, and they often look at associations between that trait and one or more variables. These studies are observational only. In other words, they collect data without interfering or affecting the patients. Generally, they are done via either questioners or examining medical records. For example, you might do a cross sectional study to determine the current rates of heart disease in a given population at a particular time, and while doing so, you might collect data on other variables (such as certain medications) in order to see if certain medications, diet, etc. correlate with heart disease. In other words, these studies are generally simply looking for prevalence and correlations.
There are several problems with this approach, which generally result in it being fairly weak. First, there’s no randomization, which makes it very hard to account for confounding variables. Further, you are often relying on people’s abilities to remember details accurately and respond truthfully. Perhaps most importantly, cross sectional studies cannot be use to establish cause and effect. Let’s say, for example, that you do the study that I mentioned on heart disease, and you find a strong relationship between people having heart disease and people taking pharmaceutical X. That does not mean that pharmaceutical X causes heart disease. Because cross sectional studies inherently look only at one point in time, they are incapable of disentangling cause and effect. Perhaps, the heart disease causes other problems which in turn result in people taking pharmaceutical X (thus, the disease causes the drug use rather than the other way around). Alternatively, there could be some third variable that you didn’t account for which is causing both the heart disease and the need for X.
Therefore, cross sectional studies should be used either to learn about the prevalence of a trait (such as a disease) in a given population (this is in fact their primary function), or as a starting point for future research. Finding the relationship between heart disease and X, for example, would likely prompt a randomized controlled trial to determine whether or not X actually does cause heart disease. This type of study can also be useful, however, in showing that two variables are not related. In other words, if you find that X and heart disease are correlated, then all that you can say is that there is an association, but you can’t say what the cause is; however, if you find that X and heart disease are not correlated, then you can say that the evidence does not support the conclusion that X causes heart disease (at least within the power and detectable effect size of that study).
Case-control studies (strength = moderate)
Case-control studies are also observational, and they work somewhat backwards from how we typically think of experiments. They start with the outcome, then try to figure out what caused it. Typically, this is done by having two groups: a group with the outcome of interest, and a group without the outcome of interest (i.e., the control group). Then, they look at the frequency of some potential cause within each group.
To illustrate this, let’s keep using heart disease and X, but this time, let’s set up a case control. To do that, we will have one group of people who have heart disease, and a second group of people who do not have heart disease (i.e., the control group). Importantly, these two groups should be matched for confounding factors. For example, you couldn’t compare a group of poor people with heart disease to a group of rich people without heart disease because economic status would be a confounding variable (i.e., that might be what’s causing the difference, rather than X). Therefore, you would need to compare rich people with heart disease to rich people without heart disease (or poor with poor, as well as matching for sex, age, etc.).
Now that we have our two groups (people with and without heart disease, matched for confounders) we can look at the usage of X in each group. If X causes heart disease, then we should see significantly higher levels of it being used in the heart disease category; whereas, if it does not cause heart disease, the usage of X should be the same in both groups. Importantly, like cross sectional studies, this design also struggles to disentangle cause and effect. In certain circumstances, however, it does have the potential to show cause and effect if it can be established that the predictor variable occurred before the outcome, and if all confounders were accounted for. As a general rule, however, at least one of those conditions is not met and this type of study is prone to biases (for example, people who suffer heart disease are more likely to remember something like taking X than people who don’t suffer heart disease). As a result, it is generally not possible to draw causal conclusions from case-controlled studies.
Probably the biggest advantage of this type of study, however, is the fact that it can deal with rare outcomes. Let’s say, for example, that you were interested in trying to study some rare symptom that only occurred in 1 out of ever 1,000 people. Doing a cross-sectional study or cohort study would be extremely difficult because you would need hundreds of thousands of people in other to get enough people with the symptom for you to have any statistical power. With a case-control study, however, you can get around that because you start with a group of people who have the symptom and simply match that group with a group that doesn’t have the symptom. Thus, you can have a large amount of statistical power to study rare events that couldn’t be studied otherwise.
Cohort studies (strength = moderate-strong)
Cohort studies can be done either prospectively or retrospectively (case-controlled studies are always retrospective). In a prospective study, you take a group of people who do not have the outcome that you are interested in (e.g., heart disease) and who differ (or will differ) in their exposure to some potential cause (e.g., X). Then, you follow them for a given period of time to see if they develop the outcome that you are interested in. To be clear, this is another observational study, so you don’t actually expose them to the potential cause. Rather, you choose a population in which some individuals will already be exposed to it without you intervening. So in our example, you would be seeing if people who take X are more likely to develop heart disease over several years. Retrospective studies can also be done if you have access to detailed medical records. In that case, you select your starting population in the same way, but instead of actually following the population, you just look at their medical records for the next several years (this of course relies on you having access to good records for a large number of people).
This type of study is often very expensive and time consuming, but it has a huge advantage over the other methods in that it can actually detect causal relationships. Because you actually follow the progression of the outcome, you can see if the potential cause actually proceeded the outcome (e.g., did the people with heart disease take X before developing it). Importantly, you still have to account for all possible confounding factors, but if you can do that, then you can provide evidence of causation (albeit, not as powerfully as you can with a randomized controlled trial). Additionally, cohort studies generally allow you to calculate the risk associated with a particular treatment/activity (e.g., the risk of heart disease if you take X vs. if you don’t take X).
Randomized controlled trial (strength = strong)
Randomized controlled trials (often abbreviated RCT) are the gold standard of scientific research. They are the most powerful experimental design and provide the most definitive results. They are also the design that most people are familiar with. To set one of these up, first, you select a study population that has as few confounding variables as possible (i.e., everyone in the group should be as similar as possible in age, sex, ethnicity, economic status, health, etc.). Next, you randomly select half the people and put them into the control group, and then you put the other half into the treatment group.The importance of this randomization step cannot be overstated, and it is one of the key features that makes this such a powerful design. In all of the previous designs, you can’t randomly decide who gets the treatment and who doesn’t, which greatly limits your power to account for confounding factors, which makes it difficult to ensure that your two groups are the same in all respects except the treatment of interest. In randomized controlled trials, however, you can (and must) randomize, which gives you a major boost in power.
In additional to randomizing, these studies should be placebo controlled. This means that the people in the treatment group get the thing that thing that you are testing (e.g., X), and the people in the control group get a sham treatment that is actual inert. Ideally, this should be done in a double blind fashion. In other words, neither the patients nor the researchers know who is in which group. This avoids both the placebo affect and researcher bias. Both placebos and blinding are features that are lacking in the other designs. In a case controlled study, for example, people know whether or not they are taking X, which can affect the results.
When you think about all of these factors, the reason that this design is so powerful should become clear. Because you select your study subjects beforehand, you have unparalleled power for controlling confounding factors, and you can randomize across the factors that you can’t control for. Further, you can account for placebo effects and eliminate researcher bias (at least during the data collection phase). All of these factors combine to make randomized controlled studies the best possible design.
Now you may be wondering, if they are so great, then why don’t we just use them all the time? There are a myriad of reasons that we don’t always use them, but I will just mention a few. First, it is often unethical to do so. For example, using these studies to test the safety of vaccines is generally considered unethical because we know that vaccines work; therefore, doing that study would mean knowingly preventing children from getting a lifesaving treatment. Similarly, studies that deliberately expose people to substances that are known to be harmful is unethical. So, in those cases, we have to rely on other designs in which we do not actually manipulate the patients.
Another reason for not doing these studies, is if the outcome that you are interested is extremely rare. If, for example, you think that a pharmaceutical causes a serious reaction in 1 out of every 10,000 people, then it is going to be nearly impossible for you to get a sufficient sample size for this type of study, and you will need to use a case-control study instead.
Cost and effort is also a big factor. These studies tend to be expensive and time consuming, and researchers often simply don’t have the necessary resources to invest in them. Also, in many cases, the medical records needed for the other designs are readily available, so it makes sense to learn as much as we can from them.
Systematic reviews and meta-analyses (strength = very strong)
Sitting at the very top of the evidence pyramid, we have systematic reviews and meta-analyses. These are not experiments themselves, but rather are reviews and analyses of previous experiments. Systematic reviews carefully comb through the literature for information on a given topic, then condense the results of numerous trials into a single paper that discusses everything that we know about that topic. Meta-analyses go a step further and actually combine the data sets from multiple papers and run a statistical analyses across all of them.
Both of these designs produce very powerful results because they avoid the trap of relying on any one study. One of the single most important things for you to keep in mind when reading scientific papers is that you should always beware of the single study syndrome. Bad papers and papers with incorrect conclusions do occasionally get published (sometimes at no fault of the authors). Therefore, you always have to look at the general body of literature, rather than latching onto one or two papers, and meta-analyses and reviews do that for you. Let’s say, for example, that there are 19 papers saying that X does not cause heart disease, and one paper saying that it does. People would be very prone to latch onto that one paper, but the review would correct that error by putting that one study in the broader context of all of the other studies that disagree with it, and the meta-analysis would deal with it but running a single analysis over the entire data set (combined form all 20 papers).
Importantly, garbage in = garbage out. These papers should always list their inclusion and exclusion criteria, and you should look carefully at them. A systematic review of cross sectional analyses, for example, would not be particularly powerful, and could easily be trumped by a few randomized controlled trials. Conversely, a meta-analysis of randomized controlled trials would be exceedingly powerful. Therefore, these papers tend to be designed such that they eliminate the low quality studies and focus on high quality studies (sample size may also be a inclusion criteria). These criteria can, however, be manipulated such that they only include papers that fit the researchers’ preconceptions, so you should watch out for that.
Finally, even if the inclusion criteria seem reasonable and unbiased, you should still take a look at the papers that were eliminated. Let’s say, for example, the you had a meta-analysis/review that only looked are randomized controlled trials that tested X (which is a reasonable criteria), but there are only five papers like that, and they all have small sample sizes. Meanwhile, there are dozens of case-control and cohort studies on X that have large sample sizes and disagree with the meta-analysis/review. In that case, I would be pretty hesitant to rely on the meta-analysis/review.
The importance of sample size
As you have probably noticed by now, this hierarchy of evidence is a general guideline rather than a hard and fast rule, and there are exceptions. The biggest of these is caused by sample size. It’s really the wild card in this discussion because a small sample size can rob a robust design of its power, and a large sample size can supercharge an otherwise weak design.
Let’s say, for example, that there was a meta-analysis of 10 randomized controlled trials looking at the effects of X, and each of those 10 studies only included 100 subjects (thus the total sample size is 1000). Then, after the meta-analysis, someone published a randomized controlled trial with a sample size of 10,000 people, and that study disagreed with the meta-analysis. In that situation, I would place far more confidence in the large study than in the meta-analysis. Honestly, even if that study was a cohort or case-controlled study, I would probably be more confident in its results than in the meta-analysis, because that large of a sample size should give it extraordinary power; whereas, the relatively small sample size of the meta-analysis gives it fairly low power.
Unfortunately, however, there are very few clear guidelines about when sample size can trump the hierarchy. The lowest level studies generally cannot be rescued by sample size (e.g., I have great difficulty imaging a scenario in which sample size would allow an animal study or in vitro trial to trump a randomized controlled trial, and it is very rare for a cross sectional analysis to do so), but for the more robust designs, things become quite complicated. For example, let’s say that we have a cohort study with a sample size of 10,000, and a randomized controlled trial with a sample size of 7000. Which should we trust? I honestly don’t know. If both of them were conducted properly, and both produced very clear results, then, in the absence of additional evidence, I would have a very hard time determining which one was correct.
This brings me back to one of my central points: you have to look at the entire body of research, not just one or two papers. The odds of a single study being flawed are fairly high, but the odds of a large body of studies being flawed are much lower. In some cases, this will mean that you simply can’t reach a conclusion yet, and that’s fine. The whole reason that we do science is because there are things that we don’t know, and sometimes it takes many years to accumulate enough evidence to see through the statistical noise and detect the central trends. So, there is absolutely nothing wrong with saying, “we don’t know yet, but we are looking for answers.”
Conclusion
I have tried to present you with a general overview of some of the more common types of scientific studies, as well as information about how robust they are. You should always keep this in mind when reading scientific papers, but I want to stress again, that this hierarchy is a general guideline only, and you must always take a long hard look at a paper itself to make sure that it was done correctly. While doing so, make sure to look at its sample size and see if it actually had the power necessary to detect meaningful differences between its groups. Perhaps most importantly, always look at the entire body of evidence, rather than just one or two studies. For many anti-science and pseudoscience topics like homeopathy, the supposed dangers of vaccines and GMOs, etc. you can find papers in support of them, but those papers generally have small sample sizes and used weak designs, whereas many much larger studies with more robust designs have reached opposite conclusions. This should tell you that those small studies are simply statistical noise, and you should rely on the large, robustly designed studies instead.
Suggested reading:

 t week, I wrote a post on the hierarchy of scientific evidence which included the figure to the right. In that post, I explained why some types of scientific papers produced more robust results than others. Some people, however, took issue with that and accused me of committing a genetic fallacy because I was attacking the source of their information rather than the information itself. They were specifically unhappy about my claim that personal anecdotes, gut feelings, counter-factual websites, etc. did not constitute scientific evidence. After all, how dare I assert that their opinions weren’t as valuable as a carefully controlled study (note the immense sarcasm). In reality, of course, my argument was not fallacious, and they were simply misunderstanding how the genetic fallacy works. This misunderstanding is, however, quite common and somewhat understandable. The genetic fallacy can admittedly be very confusing. Therefore, I want to briefly explain what this fallacy is, how to spot it, and when it is and is not acceptable to criticize the source of an argument/piece of information.
t week, I wrote a post on the hierarchy of scientific evidence which included the figure to the right. In that post, I explained why some types of scientific papers produced more robust results than others. Some people, however, took issue with that and accused me of committing a genetic fallacy because I was attacking the source of their information rather than the information itself. They were specifically unhappy about my claim that personal anecdotes, gut feelings, counter-factual websites, etc. did not constitute scientific evidence. After all, how dare I assert that their opinions weren’t as valuable as a carefully controlled study (note the immense sarcasm). In reality, of course, my argument was not fallacious, and they were simply misunderstanding how the genetic fallacy works. This misunderstanding is, however, quite common and somewhat understandable. The genetic fallacy can admittedly be very confusing. Therefore, I want to briefly explain what this fallacy is, how to spot it, and when it is and is not acceptable to criticize the source of an argument/piece of information.