
The topic of confounding factors is extremely important for understanding experimental design and evaluating published papers. Nevertheless, confounding factors are poorly understood among the general public, and even professional scientists often fail to appropriately account for them, which results in junk science. Therefore, I want to briefly explain what they are, and how to deal with them. You should then apply this whenever you are reading a scientific study or proposing that a particular study should be done.
Before I can explain confounding factors, I need to explain some fundamentals of experimental design. As a general rule, when you are designing an experiment, you want to have an experimental group and a control group. These two groups should be identical except that one group (the experimental group) should receive some form or treatment (what we call the experimental factor or experimental variable) while the other should either receive nothing or receive a placebo (depending on the exact type of study being conducted). In other words, the two groups should be totally identical except for the experimental variable. When that condition is met, you can then infer that differences between the two groups are being caused by the experimental variable. In other words, if the two groups are completely and totally identical in every way except for experimental variable, then any differences in your response variable (i.e., the thing that you are measuring) must be being caused by the experimental variable, because it is the only thing that differs between the two groups (see Note 1; also note that you can also have multiple experimental groups testing different things simultaneously, but I will stick with two for now for the sake of simplicity).
This sounds all well and good, but the problem is that in reality, having two identical groups is almost never possible. This is where the topic of confounding factors come in. If you Google a definition of “confounding factors,” you’ll basically find two lines of thought. One is that a confounding factor is a third variable that actually has a causal effect. The second is that a confounding factor is simply a third variable that might have a causal effect, thus preventing you from being able to assign causation. I detest semantic debates, so I won’t waste time quibbling over which definition is better, but for the sake of this post, I am going to use the second definition, both because that is how I hear people use it more frequently in actual discussions among scientists, and because that is the concept that I am trying to convey even if you want to use a different term (i.e., I don’t care if you remember the term “confounding factor” but I do care if you remember the concept of a confounded experiment).

This is an illustration of a fully confounded experiment. Because different brands were used in each group, there is a third variable that confounds the experiment and makes it impossible to assign causation.
Let me give a simple example of how this might play out. Imagine that you have designed a product that is intended to prolong the life of a car. Thus, you get two groups of new cars, and pour the product (the experimental variable) into the engine of one group (the experimental group), while giving the other group an equivalent volume of regular engine oil (the control group). Then, you hire people to drive them around a racetrack at high speeds for weeks until they eventually die (or perhaps put them on a treadmill of sorts, I don’t pretend to know how car testing works). Then, you record how long the cars last (your response variable). Now, suppose that at the end of the experiment, you find that, on average, the experimental group lasted significantly longer than the control group. Thus, you conclude that the product works. There is one problem, however. All of the experimental cars were Toyotas, and all of the control cars were Nissans. This is what we would call a fully confounded experiment, because there is a third variable (car brand) that is also completely different between your groups. Thus, it would be impossible to use this experiment to say that the product works, because you have no way of knowing if the product actually worked or if Toyotas simply last longer than Nissans. Do you see how that works? Because of that third variable, there is no way to confidently assign causation.
That is obviously an extreme example, but this type of thing happens all the time in real experiments, and it can occur in very subtle ways. For example, let’s say that you are testing a drug on rats, and you have your rack of cages with control rats on one side of the room and your rack of cages with the experimental rats on the other side. That may not sound like a problem, but it can be. Imagine, for example, that there is a draft in your lab, and as a result, one rack experiences a different temperature than the other. Temperature can affect metabolism and a host of other biological processes, so that would confound your experiment. Similarly, perhaps people walk through one half of your lab more than the other. That could stress the rats, and stress also affects many biological processes. There could also be a slight difference in the lighting, or any other host of factors. All of that may seem minor, but it really can make big differences in your results, and when you have a fully confounded experiment like that, you simply can’t assign causation.
My rat example is also a bit extreme, because it is, once again, a fully confounded design, meaning that the confounding factor (cage position) is totally different between the two groups; however, there are also many cases where experiments are partially confounded, and they can be just as problematic. Let’s say, for example, that you are testing a drug, and your control group is made up of 90% men and 10% women, whereas your experimental group is made up of 20% men and 80% women. That is actually a problem, because women and men have biochemical differences and they often respond differently. As a result, any differences that you see could be being driven by male/female differences rather than control/treatment differences. Thus, sex is a confounding factor and makes it very difficult to assign causation (though in this case perhaps not impossible given a large enough sample size).
So how do scientists actually deal with this? As I said early on, confounding factors are everywhere, and having two totally identical groups is virtually impossible. Fortunately, there are several important strategies for dealing them: eliminating, randomizing, blocking, and measuring.
I’m going to try to stick with my car example as I explain how these work, because I think it is useful to use a hypothetical topic that is totally separate from any real or contentious issue. The experimental design that I mentioned originally where the experimental group was entirely Toyotas and the control group was entirely Nissans is a terrible one. If you actually did that experiment, you would be screwed, because there is no statistical test on the planet that could tease out the effects of Toyotas vs the effects of the treatment in a fully confounded experiment like that (see Note 2 at the end). Fortunately, most scientists aren’t that brainless. We spend a great deal of time thinking about confounding factors before doing our experiments, and we try as hard as possible to control them. So in this case, we could control this experiment by simply eliminating many of the confounding factors. For example, we could use only one brand and one model of car for both groups (thus eliminating brand as a factor). Further, we would want to control the year of the car, the factory that produced it, etc. Basically, the idea is that if you can remove a variable from your experiment, then you should do so (unless those variables are interesting to you, more on that later). Remember, ideally you want your groups to be totally, 100% identical. So to do that, you need to eliminate as many confounding factors as you possibly can.
Once you’ve done that, and you’ve gotten your two groups to be as similar as possible, you may think that you are good to go, but you actually aren’t. Once again, having two totally equal groups is virtually impossible. So even after you have controlled every confounding factor that you can think of, there there will almost certainly still be some slight variation that you aren’t aware of. For example, there may be slight inconsistencies in the manufacturing process, the steel that was used, etc. Because you don’t know what those differences are, you can’t eliminate them, but you can compensate for them by randomizing. In other words, you should take your entire pool of cars (which should already be as similar as possible) and randomly select which ones go into each group. Thus, any variation gets randomly dispersed into your two groups, rather than falling disproportionately into one group. This is an extremely powerful and important tool that should be used whenever possible. In any experiment, you should thoroughly randomize whenever possible (in this case we would also randomize our drivers).
So far so good, but what happens when you have a confounding variable that you know about, but can’t get rid of? In many cases there are practical reasons why it is impossible to get rid of confounding factors, and in other cases there are scientific reasons. For example, maybe you want to know if there is an interaction between the product and car brand (i.e., does it work better on Toyotas than Nissans?), or you may simply want your results to be as broadly applicable as possible. After all, if you only test it on Toyotas, then all that you have actually shown is that it works on Toyotas (assuming it works at all), and you are making an assumption when you apply that result to other car brands. That assumption is probably reasonable, but it would be better to actually test it.
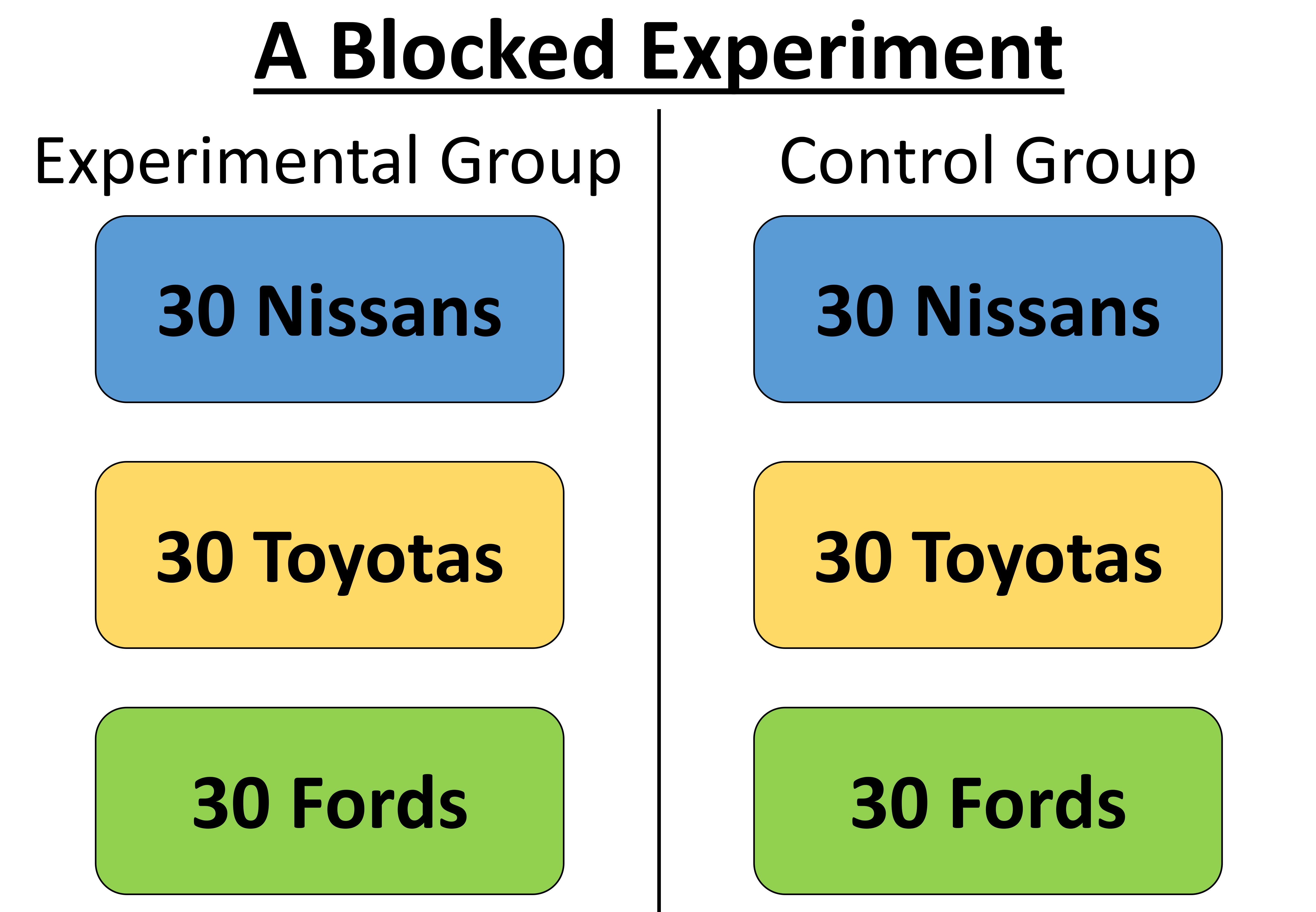
This is a blocked experimental design. Because each car brand occurs in both the experimental group and the control group, car brand can be included as a factor in the analysis, and causation can be assigned.
This is where blocking and measuring your confounding factors come in. Let’s say that you want to test this product on Toyotas, Nissans, and Fords. So, you select one model and year of each brand and control for confounding factors within car brand as much as possible, just like before. Having done that, one option would be to simply pool all three car brands and randomly select your experimental cars and control cars from that. There is nothing technically wrong with that (assuming you still include car brand as a factor in your analyses, see Note 3), but it’s not the most powerful design available to you. A much better design would be to block or group your experiment. You could, for example, have 30 of each brand in each group, in which case brand would be a blocking variable. To be clear, you still must randomize, but the randomization would take place within blocks. In other words, you would take your 60 Toyotas, and randomly assign half to each group, then you would take your Nissans and randomly assign half to each group, etc. Then, when you do your statistics at the end of the test, you would include brand as a variable in your statistical analyses, and this would be a very robust design (I won’t go into the details of why this design is so powerful here, but if you want to learn more, looking into two-factor ANOVAs is a good place to start).

This is a more complex blocked experiment. It also includes “nesting” meaning that you have car models “nested” within car brands.
You can also build on this design by including additional blocks. For example, you could have several models of car within each brand (this would then introduce yet another concept known as nesting, which I won’t go into but you can read about here). Alternatively, perhaps you are interested in how the product works in heavy duty vehicles like SUVs vs standard cars. In that case, you could have one car model and one SUV model from each car brand and include vehicle class (SUV vs car) as an additional blocking variable (again you would want to randomize within each block). You could even go one step further and have several car models and several SUV models within each brand, at which point you would have three blocks (brand, class, and model) as well as nesting. As you can see, this all becomes very complicated very quickly, and I don’t expect you to be thinking at the three-block stage right now, but I want you to be aware that blocking is a very powerful tool that lets you make sense of complex experimental designs that may, at first, appear to have serious issues with confounding factors.
Finally, let’s imagine that for some reason you can’t block your experiment. In other word, there is some confounding factor that you know about, but for one reason or another you can’t block against it. For example, perhaps all of your cars are used, rather than brand new. That would obviously greatly increase the variation in your data and would likely force you to greatly increase your sample size, but even with a larger sample size and randomization, you would still need some mechanism for dealing with the fact that some cars had been driven more than others prior to your experiment. The solution is actually quite simple, you record the pre-existing mileage on each car and include those data as a factor known as a covariate in your analyses. The idea is basically that covariates explain some of the variation in your data, so by including them in the model, you get that explanation and can compensate for the variation caused by the confounding factor. As a general rule, you should do this anytime that you have some measurable variation that can’t be eliminated or blocked (see Note 4). You should measure it, then include those measurements in the analysis.
At this point, you may be wondering what on earth the point of all of this is. After all, most of my readers aren’t scientists who are going to be designing experiments, and if you are, you should be consulting a statistician or good stats book, not reading my blog. Nevertheless, if you have read this far, then I am going to assume that you are interested in science and understanding how the world works, and I’m going to assume that this interest will invariably lead you to read some scientific literature. That is where this comes in, because not all scientists know what they are doing, and we are all prone to mistakes, so when you read a scientific paper, you should look for things like this. See if they eliminated as many confounding factors as possible, see if they blocked the experiment and included those blocks in the analyses, see if they randomized correctly, and make sure that they included measurable variation in the analyses. If they didn’t do these things, then you should be dubious of their results. If you see confounding factors that they didn’t account for, or they didn’t randomize, etc. you should think twice before accepting their conclusions (for example, see my analysis of a rat/Roundup that was not done correctly). I should also clarify here that although I have been talking specifically about randomized controlled studies in this post, what I have said applies to other designs such as cohort studies as well. The techniques that I have laid out are extremely important for dealing with confounding factors, and you should make sure that they are being used correctly when you read a study.
Related posts
- Basic Statistics Part 1: The Law of Large Numbers
- Basic Statistics Part 2: Correlation vs. Causation
- Basic Statistics Part 3: The Dangers of Large Data Sets: A Tale of P values, Error Rates, and Bonferroni Corrections
- Basic Statistics Part 4: Understanding P values
- Basic Statistics Part 5: Means vs Medians, Is the “Average” Reliable?
- Does Splenda cause cancer? A lesson in how to critically read scientific papers
- No, homeopathic remedies can’t “detox” you from exposure to Roundup: Examining Séralini’s latest rat study
- The hierarchy of evidence: Is the study’s design robust?
Notes: As you can probably tell, this topic can be quite complex, and I have had to make some simplifications and generalizations to try to get the key points across in a brief blog post. Nevertheless, there are a few things that I would like to provide some additional information on.
Note 1: When I said, “if the two groups are completely and totally identical in every way except for experimental variable, then any differences in your response variable (i.e., the thing that you are measuring) must be being caused by the experimental variable” I want to be completely clear that I was talking about two 100% identical groups (i.e. no variation between the groups whatsoever). Only then can you be totally certain that your relationships are causal, but as I explained in the post, there is always some variation. Therefore, in actual experiments, you can’t assign causation with 100% significance. This is one of the many reasons that we use statistics to tell us the probability that the result that we are observing could have arisen just by chance (more details on how that works here).
Note 2: When I said that no statistical tests could determine causation with a fully confounded experiment, I want to be clear that I am talking simply about taking the measurement variable (car lifespan) and doing a statistical test comparing care lifespan between your experimental group and treatment group. I am not talking about investigations into the mechanisms through which the product worked. In other words, if you had a hypothesis about the mechanism that the product should use, then perhaps you could examine the cars in the two groups to try to actually look at their mechanical properties, but that is a very different thing from the type of statistics that I have been talking about here.
Note 3: I have been talking about blocks as groups that you deliberately design, but I should point out that for many statistical tests, you can include blocking factors even if you didn’t set up the type of nice even design that I have laid out here. For example, if you took a pool of Toyotas, Nissans, and Fords and randomly assigned them into groups instead of treating them as blocks with randomization with blocks, you could (and indeed should) still include car brand as a factor in your analysis. Your groups will probably just be a bit lopsided (i.e. out of 60 cars, 40 might get randomly selected to go into the control group and only 20 might end up in the experimental group). Deliberately blocking is just generally a bit better because you can control the number of samples in each block.
Note 4: I said that you should always measure sources of variation that can’t be eliminated or blocked and include them in your experiment, but there are exceptions. Sometimes, the variation may not have anything whatsoever to do with the causation, and “over-fitting” statistical models (i.e., including unnecessary variables) is actually a problem. So, if you are in a situation where there is no reasonable mechanism through which a measurable source of variation could influence the results, don’t include it. For example, including the paint color of the cars as a factor would almost certainly be meaningless, so don’t include it. Additionally, depending on the type of statistical test that you are using, you may be able to construct several statistical models using different combinations of variables, then test which one expalins the data better using things like AICs and BICs. To be clear, you aren’t running a bunch of models to see which one gives you the results that you like, rather you are selecting the model that does the best job of explaining the data (this is a complex topic for another time).

It’s more complex than I ever thought, but thanks for trying to make it more understandable to the layperson, especially by using a familiar object in everyday life as an example. The problem is that most laypeople will just accept a news item or other report that says, “studies have shown that…..” because they don’t have the ability to decide otherwise.
LikeLike