

Image by Mark Philpott, shared via the Creative Commons license.
One of my main goals for this blog is to help people learn how to evaluate scientific studies. To that end, I have written several posts that dissect papers and explain either why they are robust or why they are untrustworthy (for example, see my posts on Splenda, GMOs, and vaccines). These posts have the dual goals of debunking bad science and helping people think critically, and the time has come for me to write another one of these posts. Earlier this week, someone showed me a recent study which they claimed proved that detoxing is a real thing and there are natural remedies that help your body rid itself of toxins. The study in question is, “Dig1 protects against locomotor and biochemical dysfunctions provoked by Roundup.” As you might imagine, it is less than an exceptional paper. Indeed, it was such a blatantly horrible paper that I thought it would make a good teaching tool to illustrate some of the things that you should watch out for in scientific studies. I’ll summarize the main points below, but I encourage you to read the paper for yourself and see if you can spot the problems with it before you read any further.
I have organized this post in a progression starting with problems that are concerning, but not fatal, then moving to issues that limit the papers conclusions, and ending with problems that completely nullify the paper. I have chosen this order because it is also the progression of knowledge required to spot the problems. Most people should be able to see the red flags that I will start with, so even if you don’t have the statistical knowledge to spot the more technical problems, you can still use those early warning signs as clues that the paper should be scrutinized closely before accepting it.
Authors and conflicts of interest
It is always a good idea to look at both the authors who wrote the paper and the funding sources. Some scientists have reputations for publishing crappy or even fraudulent research, and you should be wary of them. Similarly, financial conflicts of interest should make you more skeptical of a study. Having said that, I want to be absolutely, 100% clear that you cannot claim that a study is wrong simply because of the people who wrote it or their funding sources. Those things are red flags that should make you cautious and should make you look at a paper more closely, but they are not in and of themselves enough to sink a paper (i.e., using them as the basis for outright rejection is an ad hominem/genetic fallacy). Let me put it this way, if I have a study that has some sections that are unclear, but it was written by reputable scientists and did not have any conflicts of interest, then I will probably give the authors the benefit of the doubt. In contrast, if that same paper had been written by notoriously second-rate scientists and/or had serious conflicts of interest, I would be far less willing to give the authors a pass. Another consideration is the general body of literature surrounding the paper. Extraordinary claims require extraordinary evidence, and it is always suspicious when a paper that conflicts with a large body of literature was also written by a fringe scientist and funded by people who stand to benefit from the paper.
Now that all of that has been said, let’s look at the paper itself. The first thing that jumps out is the fact that the final author on this paper is Gilles-Éric Séralini (the last author position is usually reserved for the most senior scientist who was in charge of the overall project). Séralini, for anyone who doesn’t know, is infamous for publishing low-quality, fringe studies in opposition to biotechnology (specifically GMOs). Indeed, he was the author on the infamous rat study which purported to show that GMOs caused cancer in rats, but actually only showed that Séralini doesn’t understand the concept of a proper control. Indeed, the study was so horrible that it was retracted, at which point, Séralini re-published it through a minor and questionable journal that didn’t even bother to send the paper out for review (hardly the actions of a proper scientist).
We aren’t off to a good start, but things get even worse when we look at the funding. The paper is about the supposed benefits of a homeopathic product known as Digeodren (aka Dig1), but it was funded by the company that produces Digeodren (Sevene Pharma). The authors try to get around this by saying, “The authors declare that they have no competing interests. The development of Dig1 by Sevene Pharma was performed completely independently of its assessment,” but that is just a red herring. The fact that the development and testing of Digeodren were separate is completely irrelevant. The point is that the study was funded by the same company that both produces Digeodren and stands to benefit from it. That is, by any reasonable definition, a serious conflict of interest.
Again, to be 100% clear, I am not saying that the study is invalid because it was funded by Sevene Pharma, nor am I saying that it is invalid because it was conducted by Séralini, but, both of those things are serious red flags, and the rest of the study will need to be impeccable if we are going to overlook them.
The journal that published the paper
Another quick and easy thing to look at is the quality of the journal that published the paper. You need to be careful when using this tool, however, because there is plenty of good research that is published in minor journals simply because it is not of a “broad enough scope” or “wide enough impact” to interest major journals. So you need to judge journal quality against the claims being made in a paper. In other words, when a paper is making extraordinary claims but was published in a minor journal, you should be skeptical. As with the authors and conflicts of interest, however, this is not enough to sink a paper, but it is a red flag to watch out for.
So how does our paper do? Well, it is claiming not only that a homeopathic remedy works (more on that in a minute), but also that it can help to remove toxins from your body. Both of those are extraordinary claims that fly in the face of a large body of literature. In other words, if those claims were well supported, then this paper would be of extremely wide interest and should be published in a top journal. Therefore, the fact that it showed up in a fringe journal (BMC Complementary and Alternative Medicine) is yet another warning sign that something is seriously wrong with it.
Extraordinary claims require extraordinary evidence
As alluded to earlier, you should always consider the a prior plausibility of the claims being made in a paper (i.e., how likely are they to be true given the results of other studies). In other words, if a paper is simply reporting something that dozens of other papers have reported, then you don’t need to be too critical (you should still evaluate it, but it requires less scrutiny). In contrast, when a paper is reporting something extraordinary that conflicts with numerous other papers, then the paper needs to present extraordinary evidence to support its claims.
In this case, the claims of the paper are in fact quite extraordinary. First, it is testing a homeopathic remedy. I explained the folly of homeopathy in more detail here, but in short, it relies on the utterly absurd notions that diluting something makes it stronger, like cures like, and water has memory. In other words, homeopathy violates several of our most fundamental scientific concepts. Again, that does not automatically mean that it is wrong because it is always technically possible (albeit very unlikely) that those concepts are in fact flawed. However, if you want to claim that they are flawed, you need to provide some extraordinary evidence, and in the case of homeopathy, that evidence is nowhere to be found. Indeed, systematic reviews of the literature show that homeopathy is nothing more than a placebo. Similarly, detox supplements, shakes, foot baths, etc. are scams. Your body already does a very good job of keeping potentially harmful chemicals at safe levels, and no natural remedies have been shown to actually remove toxins.
Given the weight of evidence against the claims being made by this paper, it would need to be an outstanding study to be convincing. It would need enormous sample sizes, extremely rigorous controls, careful statistics, etc. In other words, it would need to meet an extremely high bar, but as I will demonstrate, it fails to do that.
The importance of the introduction
You can often tell a lot about a paper by its introduction (called the “Background” in this journal). This is where authors are supposed to review the current state of knowledge on the topic of the paper and make the case for why their study is interesting and important. When authors fail to do that convincingly, it is often a sign of underlying problems with the study.
In this case, the introduction is quite short and has several irregularities. First, multiple of the papers that were cited were other Séralini studies. That is not a good sign. There is a lot of other relevant literature out there that should have been included (much of which disagrees with Séralini’s studies). Similarly, several of the cited studies are questionable at best. Indeed, one of their central arguments hangs on a citation to the aforementioned GMO rat study that was so flawed that it was retracted.
Further, the authors cited several relevant papers about the properties of the active ingredients in Digeodren, but they totally failed to mention that Digeodren is a homeopathic remedy and those active ingredients are only present at extremely low concentrations (in this case about 1–10 parts in 100,000). They did mention this briefly in the methods, but its omission from the introduction is extremely troubling. If you are going to do a study on homeopathy, you had dang well better discuss the existing literature on that topic.
Methods: animal trials
Now we finally get to the core of the paper itself, and the first thing that jumps out is the fact that this was an animal trial. As I explained in more detail here, humans have a different physiology than other animals. As such, animal studies have a fairly limited applicability to humans. Therefore, they should be used to identify treatments that are good candidates for human trials, but you cannot jump from saying that something works in rats to saying that it works in humans. To be clear, I am not saying that the results of animal studies are wrong. Indeed, in many cases, the drug in question does in fact work in the species that was being tested, but the fact that it worked in that species does not automatically mean that it will work in humans. As a result, you need to be careful about applying the results of animal studies to humans.
Methods: experimental design
Their experimental design was pretty simple. They took a group of 160 rats and randomly divided them into four groups of 40. One group was kept as a control and did not receive any form of treatment, one group received Roundup in its water, one group received Digeodren in its water, and one group received both Digeodren and Roundup in its water. That’s not a terrible design, but it is also not a great design. A much better approach would have been to include a blocking element.
Imagine, for example, there was a slight thermal gradient in the lab where the rats were housed, and the cage rack containing the control mice ended up being on the warm end, while the cage rack with the Roundup mice ended up being on the cool end. That introduces a new variable and can have dramatic effects on the study. You’d be surprised how much a little thing like that can skew a result. Thus, a much better approach is to do what is known as “blocking.” To do this, instead of having four sets of cages, with each set containing a different group, you have members of each treatment group in each set of cages. In other words, for each set of cages, you randomly select 10 cages from each of your four treatment groups, that way, each set (what we would call a “block”) has 10 individuals from each treatment group (the position of the cages within each block should also be randomized). Now, if there is a thermal gradient (or any other confounding factor), it balances out because it affects all of your treatment groups equally. Further, you can (and should) including that blocking variable in your analyses to actually test for confounding factors across your sets of cages. Failing to block the experiment like that is not always fatal to an experiment (depending on the type of experiment), but it does make me far less confident in the results, and remember, to accept this particular paper, it needs to be an extraordinarily good paper.
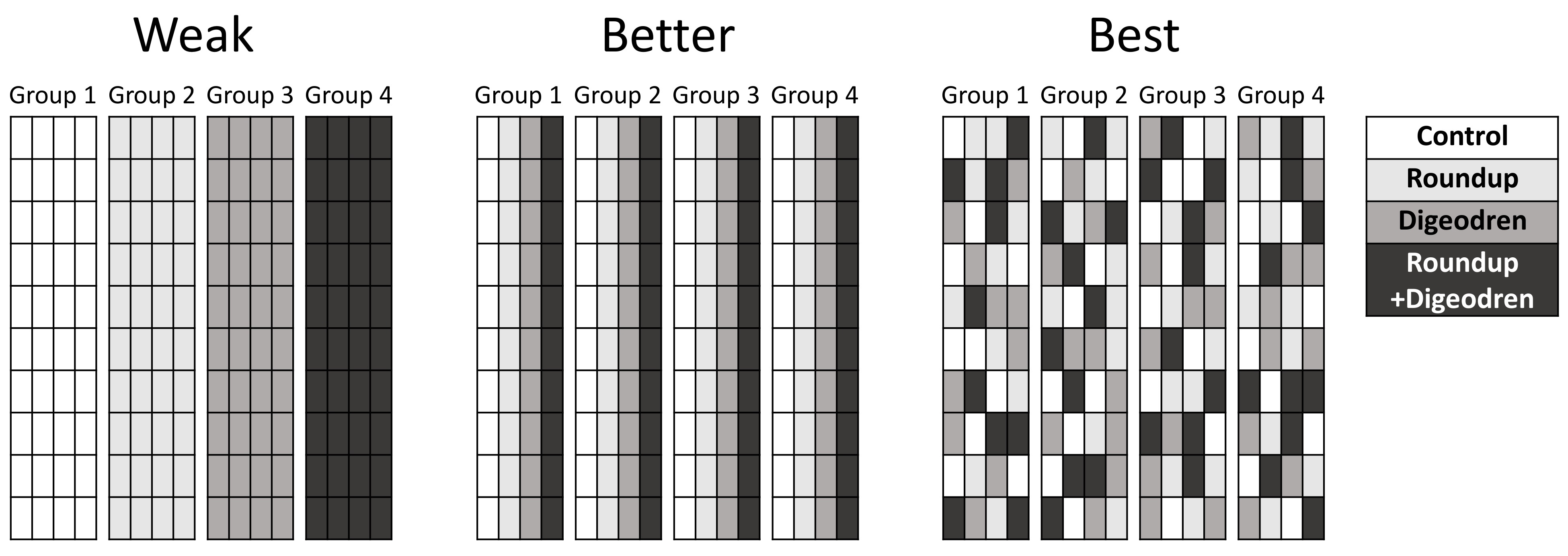
This shows three different setups for the same experiment comparing four groups of 40 rats (I am assuming one rat per cage). On the far left, you have what seems to be being described by this study (each experimental group is separate). This is a weak design. A better design is what you see in the middle where you have representatives from each experimental group within each “block.” The best design is then to randomize the location of the cages within those blocks (as seen on the far right).
A second issue is that this experiment wasn’t blinded. In other words, the researchers knew which rats were in each treatment group. That makes it very easy for their biases to inadvertently influence the experiment, especially given that one of the researchers has a reputation for publishing agenda-driven papers (again, even a slight difference in how the rats were treated could have affected things).
Note: the authors were a bit vague about how their cages were set up, so it is not clear how many rats were in each cage or how many sets of cages there were. However, it is clear that they did not use a proper blocking design.
Methods: The doses
Anytime that you are looking at a toxicology study, you have to look at the doses to see if they are reasonable. Remember, everything (even water) is toxic at a high enough dose. So when a study is looking at an environmental chemical like Roundup, it is important that they use a dose that you would realistically be exposed to in the environment. Otherwise, the study has no real applicability.
In this study, the rats in the Roundup group were given 135mg/kg of Roundup daily. After converting that to a human dose, we find that it is the equivalent of a human consuming 21.9 mg/kg daily. That is an insanely high dose. The exact allowable daily intake (ADI) for glyphosate (i.e. Roundup) varies by country, but it is much lower than that. In Australia, for example, it is 0.3 mg/kg, whereas the WHO sets it as 1 mg/kg. The dose in the experiment is also well above the levels that people are normally exposed to. Even if I want to be generous, and assume the questionable estimates put forth by the “detox project” are correct and people in the US are eating up to 3 mg/kg of glyphosate daily, the dose that the rats received is still seven times that!
To put it simply, this study is worthless because the dose is so unrealistic. Even if the authors had successfully demonstrated that Digeodren did something useful when faced with those levels, that would not in any way shape or form indicate that it does anything useful when exposed to normal levels of Roundup.
Methods: Statistics
Finally, we get to the biggest problem with this study (IMO), and this one would sink it even if it was the only thing wrong with the paper. It is a problem that I write about a lot on this blog, so you may already know where I am going with this. The problem is multiple comparisons. In technical terms, the authors failed to control the family-wise type 1 error rate. In laymen’s terms, this was a statistical fishing trip. They simply did enough comparisons that they eventually got a few that were “significant” just by chance.
I’ve previously written lengthy posts about this, but to be brief, standard statistical tests like what the authors used rely on probabilities for determining statistical significance. In other words, the report “P values” that show you the probability of getting a result of the same effect size or greater than the effect size that you observed if there is not actually an effect. It’s not technically correct, but you can think of this as the probability that you could get your result just by chance. To apply this to our study, they were looking for differences among their groups, so the P values were the probabilities of getting differences as large or greater than the differences that they observed if the treatments don’t actually cause a difference. To actually determine if something is “statistically significant” we compare it to a pre-defined threshold known as “alpha.” In biology, the alpha value is usually 0.05, so any P value less than that is considered significant. What a P value of 0.05 really means, however, is that there is a 5% chance that you could get a difference that large or larger just by chance. This is really important, because it means that you will occasional get “significant” results that arose just by chance, and we call those statistical flukes type 1 errors.
Following all of that, it should make intuitive sense that as you make more comparisons, the odds of getting at least one false positive increase. In other words, if you do enough comparisons, you will eventually find some results that are statistically significant just by chance. So your error rate across all of your tests is actually much higher than 0.05. This is what we call the family-wise type 1 error rate, and it is extremely important. To compensate for it, you should do two things. First, at the outset of your study, you should have a clear prediction of what you expect to be true if your hypothesis is correct, and you should only make the comparisons that are necessary for testing that predication. You should not make a whole bunch of haphazard comparisons and hope that something significant comes out. Second, if you end up using multiple tests to answer the same question (e.g., does drug X work?) then you need to control the family-wise error rate by adjusting your alpha value (this is usually done through a Bonferroni correction). In its simplest terms, this makes the alpha more stringent as you increase the number of comparisons that you do.
So, how did our intrepid scientists do? In short, not well. They made a whopping 29 comparisons, only 8 of which showed any form of significance, and only 6 of which showed significance in a direction that would suggest that Digeodren does anything useful. Further, they did not control the error rate among these tests. In other words, they did exactly the opposite of what you are supposed to do. They went on a fishing trip looking for significance rather than only testing a small set of pre-defined expectations. They made so many comparisons that they got some statistically significant results just by chance. To put this another way, if I set up the exact same experiment with four groups of rats, but I did not give any of them Digeodren or Roundup, and I made the same 29 comparisons among those four groups, I would expect to get several significant results, even though I treated all four groups exactly the same. Their results are statistical flukes, nothing more.
Finally, they did not report their P values for each comparison, which means that we can’t even properly assess their results (see the note below). If they had reported a table of P values like they should have, we could do the Bonferroni correction ourselves, but since they failed to do that, we have nothing to go on.
To be clear, in most cases, the fact that an author did not control their error rate would not automatically mean that their results were statistical flukes, but it would mean that we should consider their paper untrustworthy and reject it. However, in this particular case, there is another important factor to consider. Namely, all of the existing evidence that homeopathy doesn’t work. When you consider that evidence, and the low quality of the experimental design of this particular study, the most rational conclusion is that the results are wrong rather than simply untrustworthy.
Note: If you read the paper, you will see a reference to a Bonferroni test as well as P values, but they only used those within a test rather than across tests. In other words, the tests that they were using (ANOVA and Kruskal-Wallis) make comparisons among several groups (in this case the four treatment groups) and report a single P value that tells you whether or not at least one significant difference exists among those groups. Then, if you get a significant result, you make pairwise comparisons among all of your groups and get individual P values for each comparison. So they reported the P values and controlled the error rates for those individual comparisons within each ANOVA, but I am talking about the P values across ANOVAs, because you should never even do the individual comparisons unless the ANOVA itself is significant, and if you don’t control the error rate across ANOVAs (as they didn’t), a lot of your ANOVAs will be false positives. In other words, they did 29 ANOVAs/Kruskal-Wallis tests, each of which compared four groups, and they controlled the error rates for the post-hoc comparisons of the four groups, but not for the ANOVAs themselves.
Conclusion
In summary, this paper is riddled with problems and is little more than a steaming pile of crap. It had major conflicts of interest, was written by an author with a reputation for publishing shoddy, agenda-driven studies, it was published in a fringe journal, it made inadequate references to the relevant literature, the experimental design was sub-par and failed to incorporate blinding procedures, and (most importantly) it made an astounding 29 comparisons without bothering to control the error rate. This paper is a statistical fishing trip. The authors simply made so many comparisons that they eventually got a few that were significant just by chance. This is a common tactic that is frequently employed by pseudoscientists (and sometimes legitimate researchers as well) and you should learn to spot it.

“It’s not technically correct, but you can think of this as the probability of getting your result just by chance.”
You are right that this is not technically correct. In fact, this is completely false. The p-value is the probability of observing what you observe, or something more extreme, assuming that no difference exist (as you also state). So it is the probability that chance alone COULD cause at least as big difference as you observe if there was no real effect. That is not the same as the probability that chance DID cause your observations, because it excludes the possibility that there may in fact be a real difference. This is one of the most common misinterpretation of what the p-value represents.
I completely agree with you regarding the quality of this paper. But when you state that they did 29 comparisons, of which 8 turned out significant, how can you then conclude that all of these are statistical flukes or type 1 errors? They sure can be, but you cannot conclude that they are. That is too simple.
To me the extreme dose and the experimental setup is by far the biggest deal, not the statistics. As you say, they doesn’t state how many animals was caged together, which makes it impossible to properly identify the experimental unit. I’m pretty sure they weren’t singly housed, so the n in each group is most certainly much less than 40. This could be a major source of type 1 errors. ,
I’m a big fan of your blog, and always recommend your posts to colleagues, keep up the good work!
LikeLike
Thank you for your comment and support of my blog.
Based on your comment, I have changed the wording of my statement on P values to improve clarity; however, I would contend that the original wording did imply “could” rather than “did” because I said “the probability of getting” not “the probability that you got.” Nevertheless, that is a semantic quibble. I acknowledge that you are correct and my wording was not as clear as it should have been, so I have attempted to correct it.
Similarly, I agree with you that the fact that they did not control the error rate does not automatically mean that their results are type 1 errors; however, in this particular case that seems (at least to me) like the most parsimonious explanation given the enormous existing body of literature that has shown that homeopathy doesn’t work. As you point out, however, the experimental design could also be part of what is causing spurious results. I have added a few lines to try to clarify this.
I think that you are also probably right about the cages. I was trying to be generous, but in reality they probably didn’t have one rat per cage, in which case cage should have been a factor in their model.
LikeLike
Thanks for giving me a chance to think again. It has been years since I left real math behind in physics grad school. Finding your posts could not have come at a better time. In this era of fake news, you are going to have a lot of fun.
LikeLiked by 1 person
Anyone else notice that they decided to switch from their ANOVA testing to a “one-tailed t-test” to find significance for both CYP2D6 and estradiol, They used in ONLY when comparing “R” and “R+D” but left the other comparisons within the same experiment to the presumably ANOVA. One-tailed t-test in science, especially drug testing is usually is a red flag, but here it is just utterly the wrong choice. Also, in their results under NA+ and K+ they write, “D had a tendency to re-equilibrate plasmatic Na + and K+, though not totally,” which even for a vague statement like that is incorrect. They did not compare (or at least not show) any significant difference between R vs R+D for NA+ as it appears to not have ANY effect. Therefore, even the “through not totally” part of that statement for Na+ is just wrong. Ahh fun times.
LikeLiked by 1 person
Sorry for the double post. I am not sure how to edit it
LikeLike
That’s a good point. You need a pretty good justification for using a one-tailed test, and they didn’t provide it, at least not that I saw (I removed the double post for you, btw).
LikeLike
Love your work – long time reader, first time poster.
Not entirely related to this post, but an interesting anecdote:
I have taken this week off to study for the second part of my cardiac surgery specialist exams, and have come down with a cold.
I went to a pharmacy today to purchase some medication, and to my dismay was dispensed pharmacy only medication by the NATUROPATH! I asked for some medication, including ones that I know would have potential for interactions, had I been taking other medications, as well as contraindications in people with certain medical conditions. How much medical/medication history did she ask for? None! How many potential side effects was I warned about? None! Not even the common possibility of rebound congestion. She took my drivers license for the phenylephrine, and sent me to the cashier.
For a group that criticises my colleagues and me for not “treating the whole individual”, nor practising “holistic care”, her own performance was certainly neither of those.
Reminds me of a naturopath an old acquaintance of mine saw, who suggested she take “natural sea salt” (cf. the Saxa variety) to treat postural dizziness. Yes, increase a substance demonstrated to increase one’s risk of cardiovascular disease long term because they are a young, otherwise healthy individual with a systolic blood pressure of 90mmHg at rest…
My apologies for anecdotal evidence, and a somewhat unveiled ad hominem attack.
Oh well… I love a good dose of homeopathy in the literature!
Would be interested to see your analysis of “The Cholesterol ‘Conspiracy'” in the future – it’s a conversation I have with countless patients in my clinical work, especially given the demonstrated efficacy of statins for secondary prevention and graft protection following coronary bypass surgery.
LikeLiked by 1 person
Hello,
I just want to pay my compliments for another wonderful piece of work: very clear, very thorough, and above all with a very high educational value (I know a few people who can learn quite a bit from this, yours truly included). And oh, yet another well-deserved kicking for scientists with an anti-science agenda.
LikeLike
I’m not an expert on homeopathy but how is Digeodren a homeopathic product? It contains a homeopathic product, how does that make it a homeopathic product? Alcohol is a poison but a little bit in a beer is a tasty beverage.
LikeLike
The company that makes it describes it as a “homepathic product” (see the bottom of this link http://sevenepharma.com.au/shop/product/34-digeodren). It does not simply contain a homepathic product, rather, that is what it is. Digeodren contains an active ingredient, but that active ingredient has been repeatedly diluted via serial dilutions, thus the product itself is a homeopathic product.
Also, beer actually is a poison…in a high enough dose. Everything is toxic if you are exposed to enough of it (but that is really beside the point).
LikeLike
That linked page does not describe it as a homeopathic product. It says one of the ingredients is “Homeopathic product”. What do you think composition means? Another analogy, bread contains flour that doesn’t make bread flour.
LikeLike
No, the composition is “Taraxacum officinalis / Dandelion D4, Berberis vulgaris / Barberry D5, and Lappa major / Burdock D4.” The D4s and D5 are descriptions that are used in homeopathy to show how much a product has been diluted. In other words, Digeogren is a homeopathic product containing D4 dilutions of Taraxacum officinalis (D4 = a 4x dilution), D5 dilutions of Berberis vulgaris, and D4 dillutions of Lappa major. Those are the active ingredients in the product, and all of them are listed as homeopathic dilutions, therefore the product itself is a homeopathic product. To put this another way, even if the “homeopathic product” at that point point of the page refers to something in Digeodren not Digeodren itself, that would mean that all 4 of the ingredients are homeopathic products, therefore it is a homeopathic product. Homeopathic products are simply extremely diluted levels of active ingredients, and that is clearly what this is.
Also, the company that makes it clearly describes it as homeopathic elsewhere
http://www.sevenepharma.com/des-complexes-homeopathiques-pour-detoxifier-lorganisme/ and you can find plenty of other places that describe it as a homeopathic product. For example, here http://www.neopharmi.ge/index.php?name=PagesG&op=page&pid=277&newlang=3english and here https://www.soin-et-nature.com/en/homeopathy-complex-board/2503-digeodren-granules-homeopathie-sevene-pharma.html
LikeLiked by 1 person
Since you seem to like analogies, what you are saying is like saying, “Aspirin is not a medicine, it contains a medicine, because it contains acetylsalicylic acid and the acid is the active ingredient that actually reduces pain.” It’s a meaningless semantic quibble.
LikeLike